JS引擎
前段时间看到pwn比赛中有考察到js引擎的题目,本人打算学习了解一下。主打一个广涉猎,在每个方向的深度方面可能还需要在后续的做题过程中积累。。。。
什么是”引擎”?
这里用引擎描述还是非常形象的,即将js代码“发动”起来(准确地给出代码运行结果的一段程序)的工具。我看到这段第一反应是:这不就是编译器吗?但是要注意,javascript是动态语言。对于动态语言来说,让其从源代码文件到可以跑起来的字节码的工具叫做解释器(Interpreter)
区别:
- 编译器是将源代码编译为另外一种代码(比如机器码,或者字节码)
- 解释器是直接解析并将代码运行结果输出。 比方说,firebug的console就是一个JavaScript的解释器。
解释型语言:程序不需要编译,程序在运行的过程中才用解释器编译成机器语言,边编译边执行,不会产生可执行的字节码文件
但是,现在很难去界定说,JavaScript引擎到底算是解释器还是编译器,因为,比如像V8(Chrome的JS引擎),它其实为了提高 JS的运行性能,在运行之前会先将JS编译为本地的机器码(native machine code),然后再去执行机器码(这样速度就快很多)
JIT(Just In Time Compilation):解决解释性语言的性能问题,主要思想是当解释器将源代码解释成内部表示的时候(类似于java字节码),JavaScript的执行环境不仅是解释这些内部表示,而且将其中一些字节码(使用率高的部分)转成本地代码(汇编代码),这样就可以被CPU直接执行,而不是解释执行,从而提高性能。
工作流水线:
字节码 → 解释器执行 → 热点探测 → JIT 编译 → 本地代码缓存 → 后续直接跳转
引擎的组成
- 编译器。主要工作是将源代码编译成抽象语法树,然后在某些引擎中还包含将抽象语法树转换成字节码
- 解释器。在某些引擎中,解释器主要是接受字节码,解释执行这个字节码,然后也依赖回收机制等
- JIT工具。一个能够JIT的工具,将字节码或者抽象语法树转换成本地代码
- 垃圾回收器和分析工具(profiler)。它们负责垃圾回收和收集引擎中的信息,帮助改善引擎的性能和功效
题目形式
通常会在文件中给出特定的patch修改文件,同时给出已经运用该引擎的对应js引擎。作为攻击者,我们需要利用js代码利用patch的地方(通常存在漏洞)来达到提权的目的。创建exp.js,利用引擎解析该js文件,触发漏洞,提权/获得flag
pwncollege V8 exploitation
level 1
第一步确定题目patch的地方,patch文件:
1 | diff --git a/src/builtins/builtins-array.cc b/src/builtins/builtins-array.cc |
V8 挂方法的“模板公式”
- 在
builtins-definitions.h加
CPP(YourBuiltin)- 在
builtins-xxx.cc写实现
BUILTIN(YourBuiltin) { ... }- 在
bootstrapper.cc挂原型
SimpleInstallFunction(isolate_, proto, "js方法名", Builtin::kYourBuiltin, 参数个数, 是否adapt);
这段patch其实就是为v8引擎新增了一个识别array.run()方法的功能,对应实现ArrayRun本质上申请一片rwx内存,将array内存的double类型值依次存入,其中会检查类型是否为double以及长度限制。然后直接跳到内存开始处执行。非常简单粗暴,思路也很简单,直接借助强大的python写double类型的shellcode,然后在js文件run对应的double类型的array,即可执行任意代码。
这里存在一点需要注意的,在执行这段shellcode时, RUID!=EUID==root。

这里如果直接execve(‘/bin/sh’)的话,在某些安全配置下,如果检测到其实时RUID != EUID(例如,从setuid程序启动),会主动丢弃特权,将EUID重置为RUID,这是一种安全保护。在题目环境下会导致权限丢失。那么稳妥的方法是直接执行能够得到flag的文件,刚好题目给了一个catflag文件,非常巧的是(其实是故意设计的):catflag的关联组与EUID相同,那么直接执行即可。

Exp.js
1 | var shellcode = [ |
level 2
依旧先看patch文件:
patch
1 | diff --git a/src/d8/d8.cc b/src/d8/d8.cc |
看懂上面代码需要了解一些关键的v8引擎原理:
将C++函数暴露给JavaScript(一种方式):
global_template->Set(isolate, "ArbWrite32",FunctionTemplate::New(isolate, ArbWrite32));实现JS 名称到 C++ 函数的映射,同时对应函数的实现参数与返回需要调用v8对应的apiv8::Isolate* isolate = info.GetIsolate();从参数中的v8回调对象中得到isolate(V8 的沙箱和资源管理单元),作为所有 V8 操作的核心上下文和资源容器指针压缩技术: V8 启用了指针压缩(Pointer Compression)机制。该机制下,堆对象的地址并不是完整的 64 位地址,而是相对于 cage base 的 32 位偏移量,然后再将32位压缩基址转换为64位完整地址。需要用
internal::PtrComprCageBase cage_base = internal::GetPtrComprCageBase();internal::Address base_addr = internal::V8HeapCompressionScheme::GetPtrComprCageBaseAddress(cage_base);来获得V8堆在进程地址空间中的起始地址(64位值)
实现的功能其实就是核心的两大原语:任意地址读➕任意地址写,以及一个获得对象在进程中的地址
假若在一个c语言写的程序中,我拿到这三个功能那么getshell的思路也就很多了。但是这是js程序中的功能,还没有那么直接简单。首先在题目的v8版本下,MAGLEV compilation机制会为多次重复的函数分配一段具有rwx的区域(并不是所有v8版本都是这样)。
1 | // 触发了MAGLEV的行为: |
那么基本思路就是在函数中嵌入getshell(以常量数据形式出现)的payload,在exp.js中反复调用对应函数使对应函数,使函数对应的机器码被分配到rwx的区域中。修改指针指向shellcode。
1.如何获得shellcode地址?
在js中,函数对象的地址并不是直接指向机器码,而是一个结构体。想要获得函数真实对应的机器码需要三级跳转:函数对象 → CodeDataContainer → instruction_start(常量的地址)
其中每一层跳转都需要找到相应的偏移(后者是前者的结构体成员)。
2.如何劫持程序流?
既然已经知道intruction_start指向函数机器码的开始,理所当然的劫持code结构体中的instruction_start成员为shellcode地址就可以执行shellcode了
3.怎么存shellcode?
一般选择 Float64数组(双精度浮点数)
8字节对齐:正好是x64指令的自然大小
IEEE 754标准:精确的二进制表示
MAGLEV友好:浮点常量常被嵌入代码段
无类型混淆:纯浮点数,V8优化简单
不过需要注意由于浮点数是八字节的表示形式 ,去掉前面两个字节的操作 ,剩下的六个字节就是我们可控的内容 ,然后为了能写成rop的形式,所以6个字节里要已jmp结尾,用来跳到下一个gadget片段,所以我们每一个gadget可以写四字节的内容+一个jmp
Shellcode_generator:
1 | from pwn import * |
js_tranlater:
1 | function convert(){ |
Exp.js:
1 | function shellcode(){ |
 。题目中有些关键的栈操作函数如果不在ida中转化变量为结构体还是很难逆的。
。题目中有些关键的栈操作函数如果不在ida中转化变量为结构体还是很难逆的。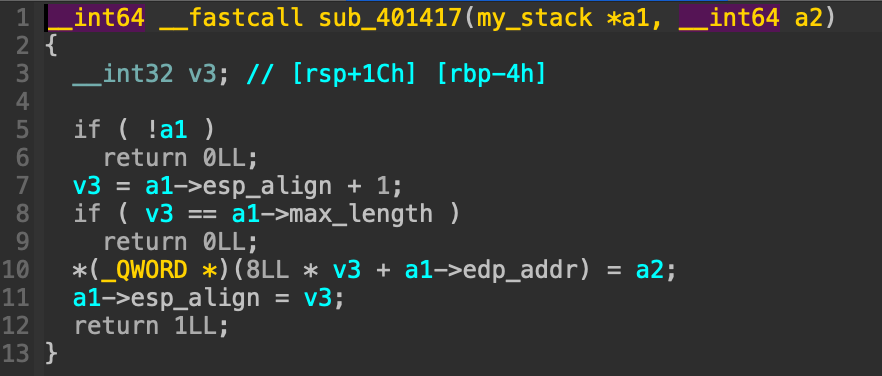 这里实现了栈的push功能。关键逻辑还是在解析函数中,对于存储opcode的栈依次弹栈并switch_case判断opecode跳到不同操作函数中(已经算是非常直接的解析逻辑了。
这里实现了栈的push功能。关键逻辑还是在解析函数中,对于存储opcode的栈依次弹栈并switch_case判断opecode跳到不同操作函数中(已经算是非常直接的解析逻辑了。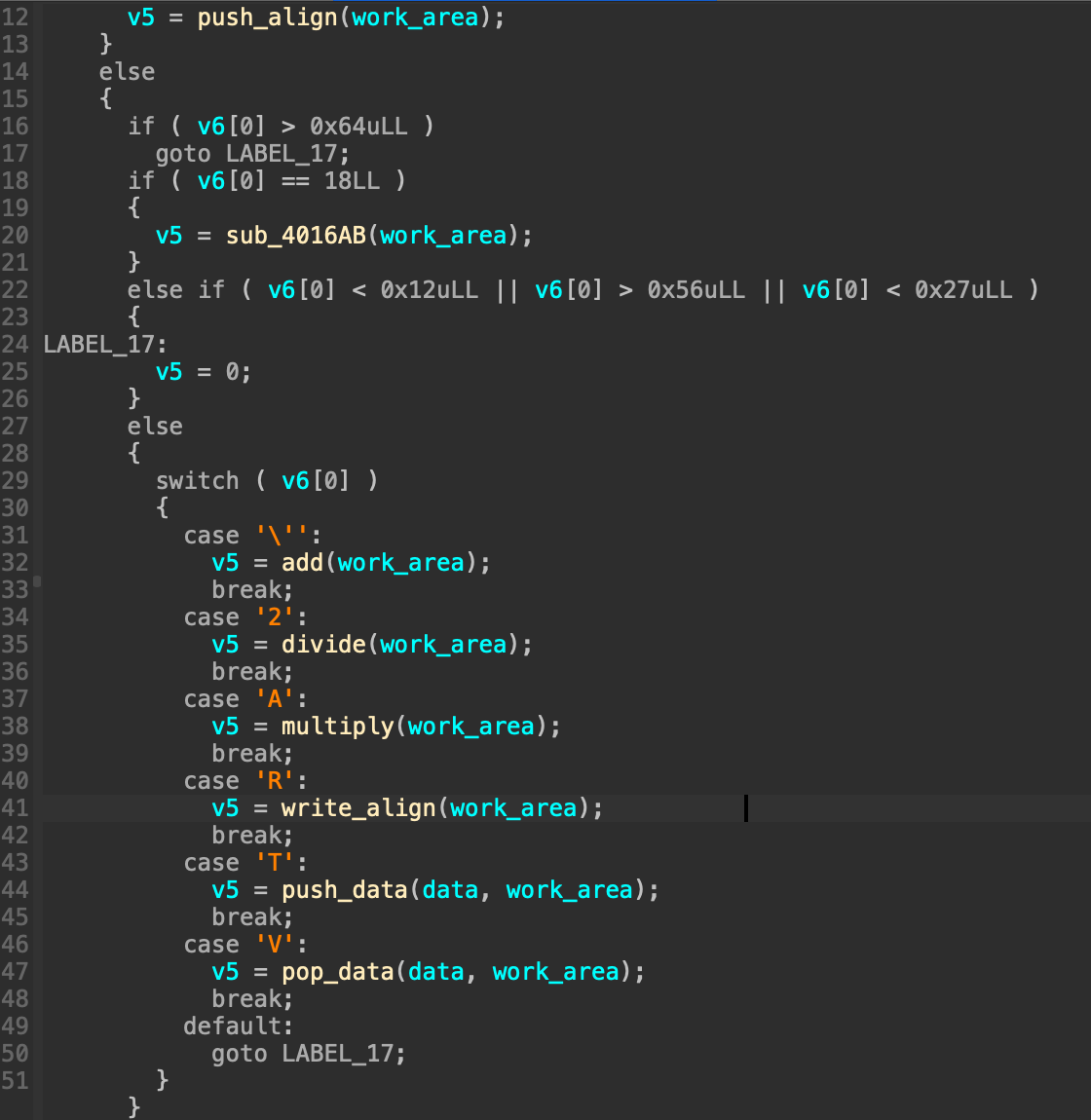


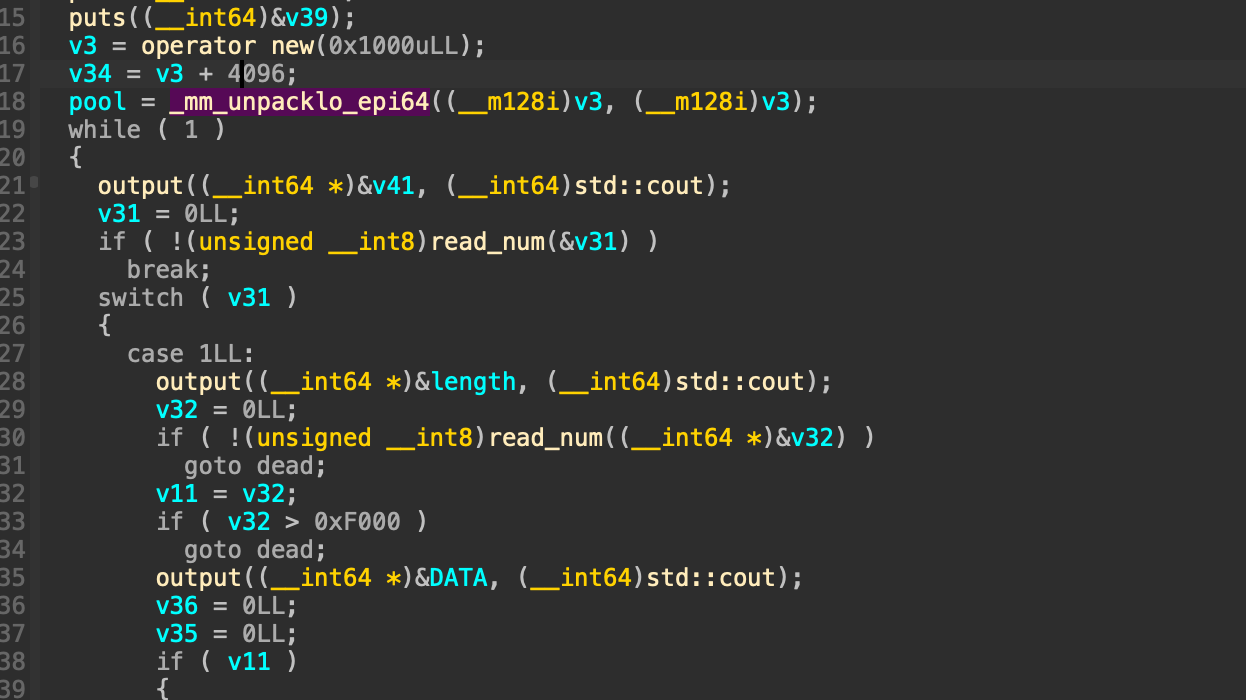 这里在菜单循环前new了一个0x1000大小的堆块,并将栈变量指向它。这是一个预分配的内存池,栈上存在0x10的变量分别存其基址以及游标(代表内存池的使用情况)。其实内存池与我之前接触的大部分堆题中的bss段存堆信息的作用是一样的。将这些信息存在动态内存中更加灵活,实现可拓展性。当然,如果我们能够通过构造堆overlapping或者堆溢出能控制这个内存池中的数据那么就达成了任意地址读写了。这里的内存池存在extend函数,总体逻辑就是如果游标以及到堆块的尾部的话就申请2倍自己大小复制原先内容然后free掉自己。这也一定程度上允许我们控制对应堆块的相对位置(本题没有用到)。
这里在菜单循环前new了一个0x1000大小的堆块,并将栈变量指向它。这是一个预分配的内存池,栈上存在0x10的变量分别存其基址以及游标(代表内存池的使用情况)。其实内存池与我之前接触的大部分堆题中的bss段存堆信息的作用是一样的。将这些信息存在动态内存中更加灵活,实现可拓展性。当然,如果我们能够通过构造堆overlapping或者堆溢出能控制这个内存池中的数据那么就达成了任意地址读写了。这里的内存池存在extend函数,总体逻辑就是如果游标以及到堆块的尾部的话就申请2倍自己大小复制原先内容然后free掉自己。这也一定程度上允许我们控制对应堆块的相对位置(本题没有用到)。 输出逻辑的判断是对于每两字节判断是否同时为0作为输出结束标识。
输出逻辑的判断是对于每两字节判断是否同时为0作为输出结束标识。

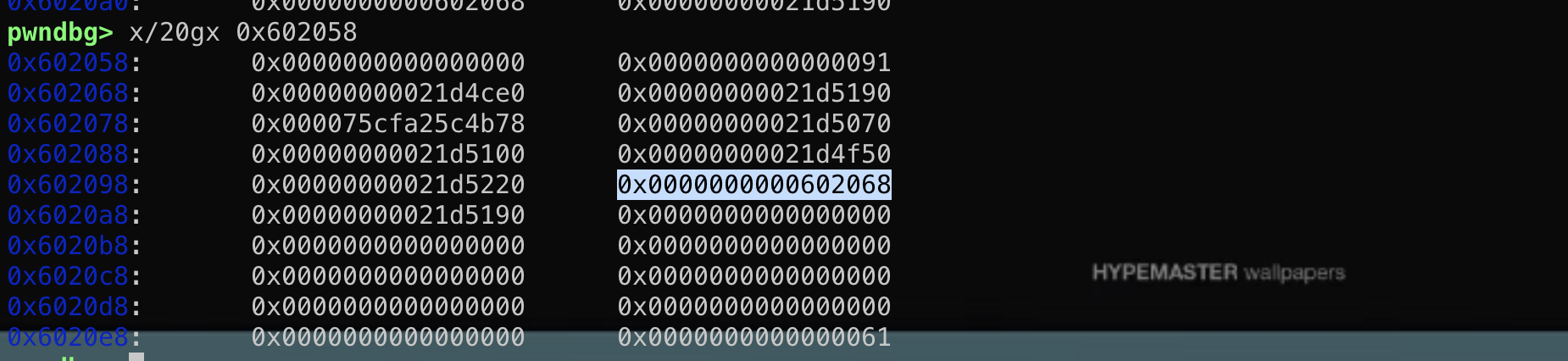
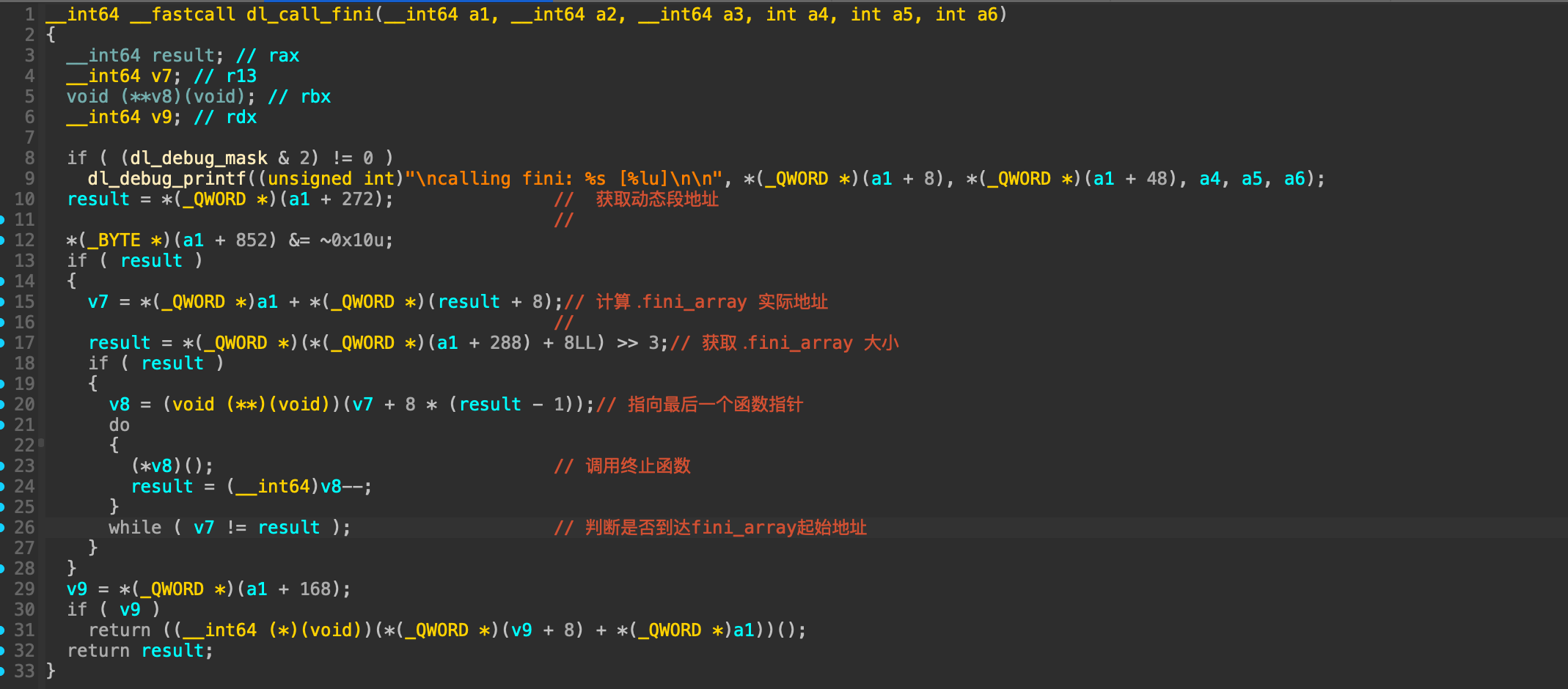
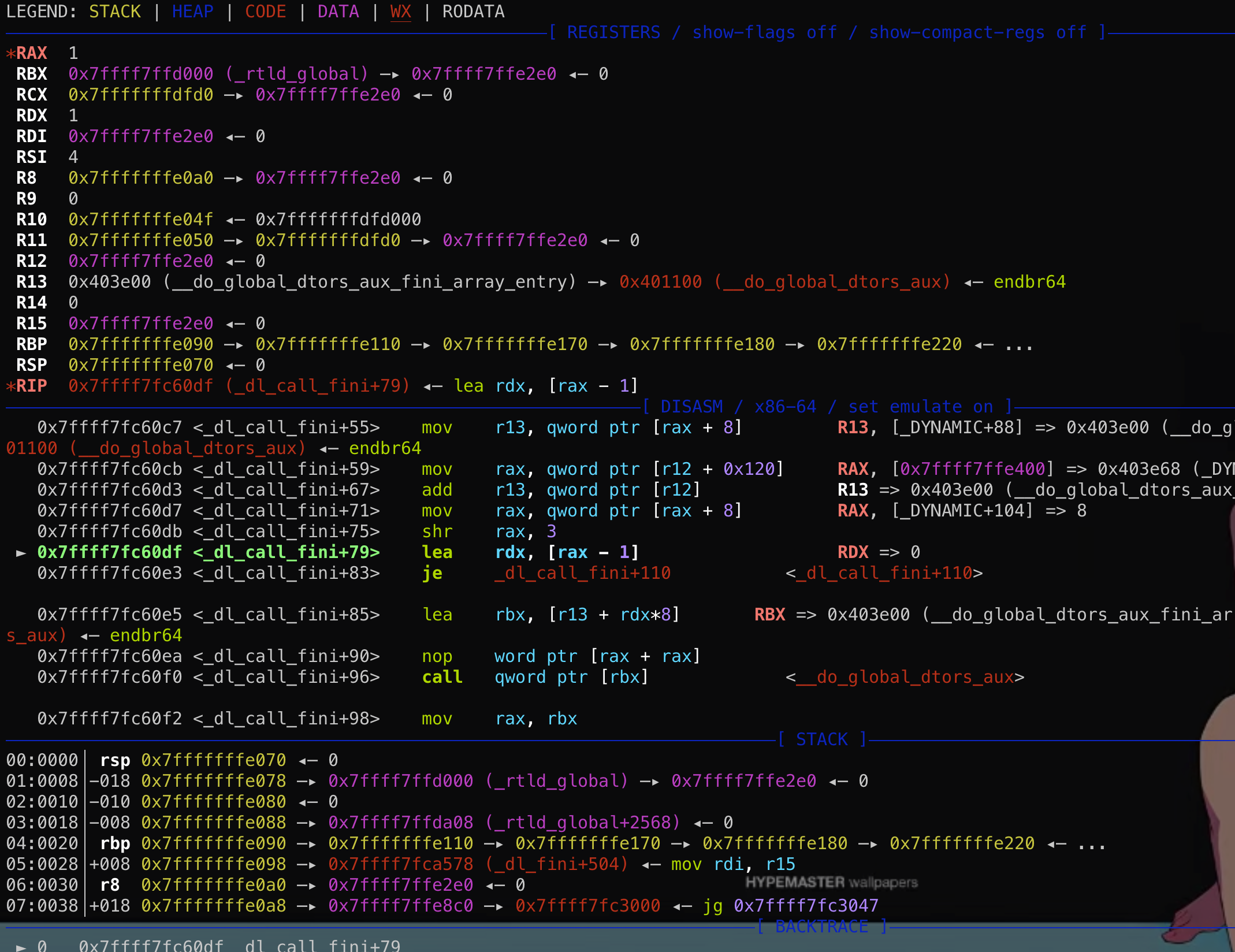
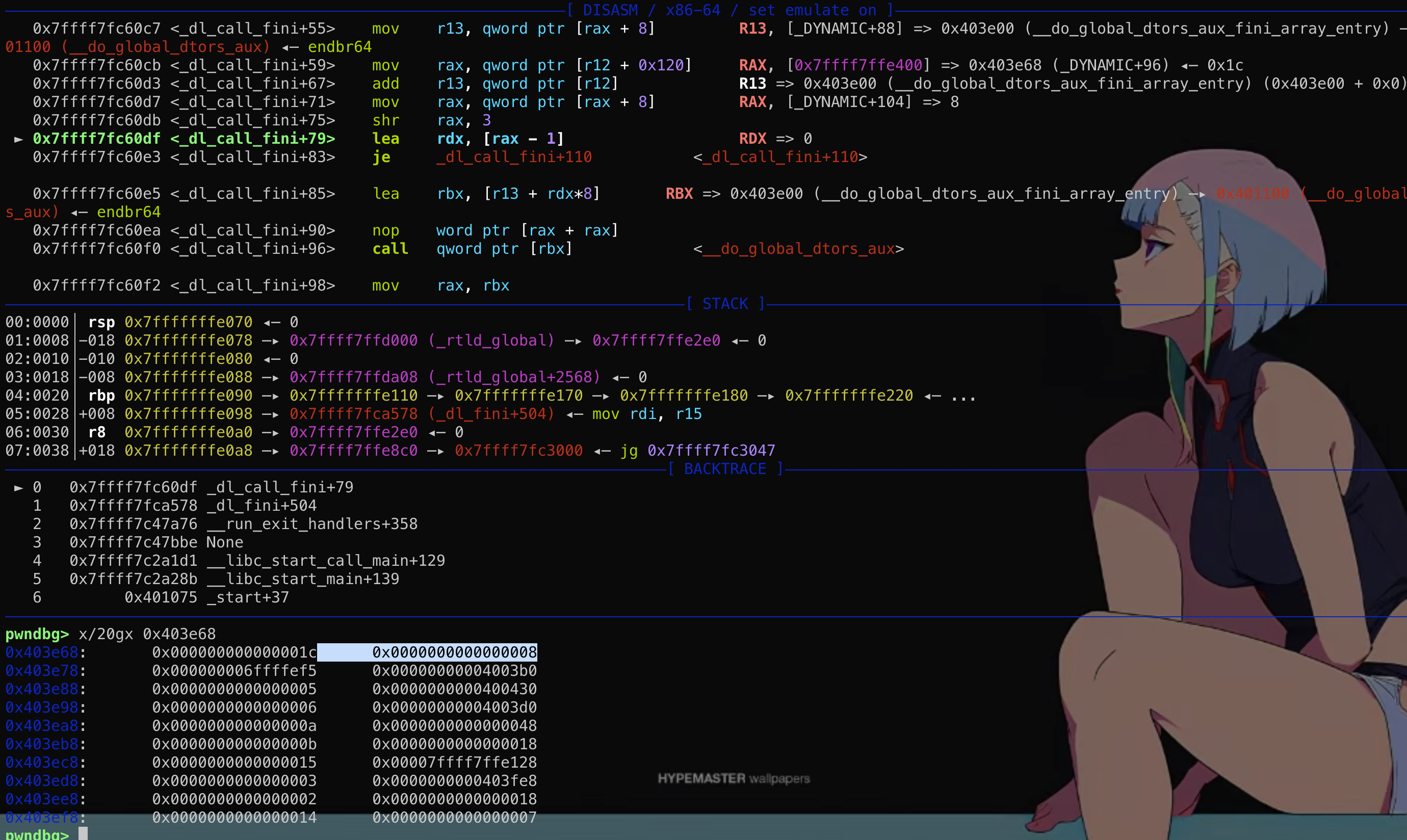
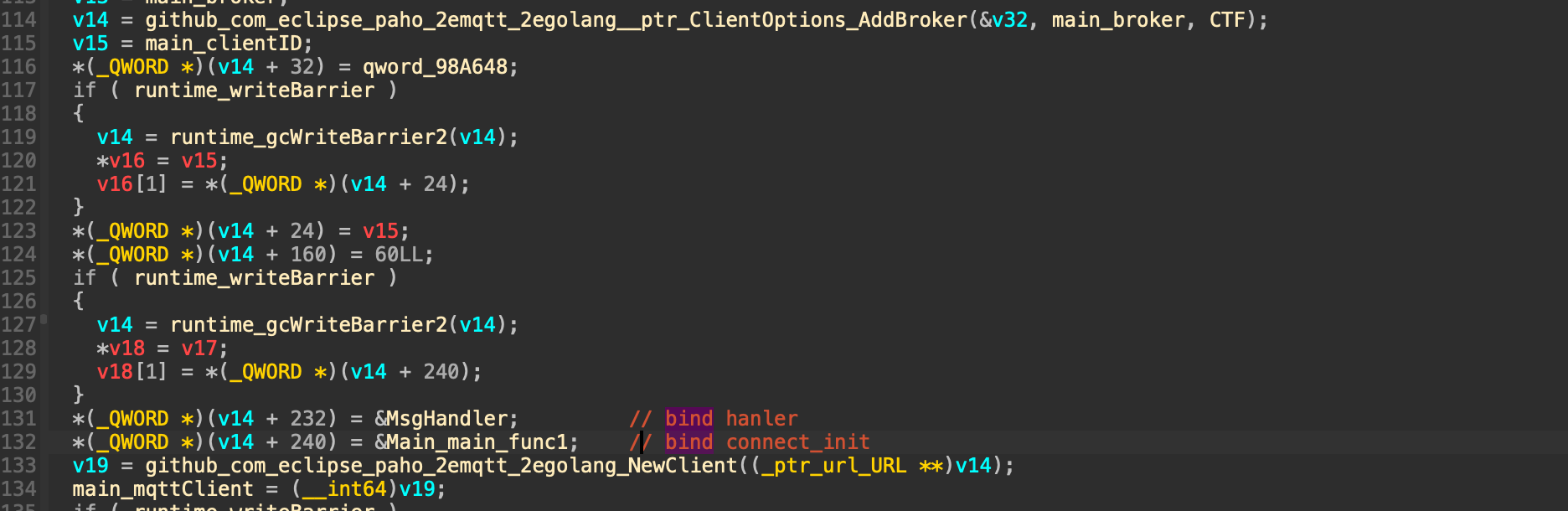
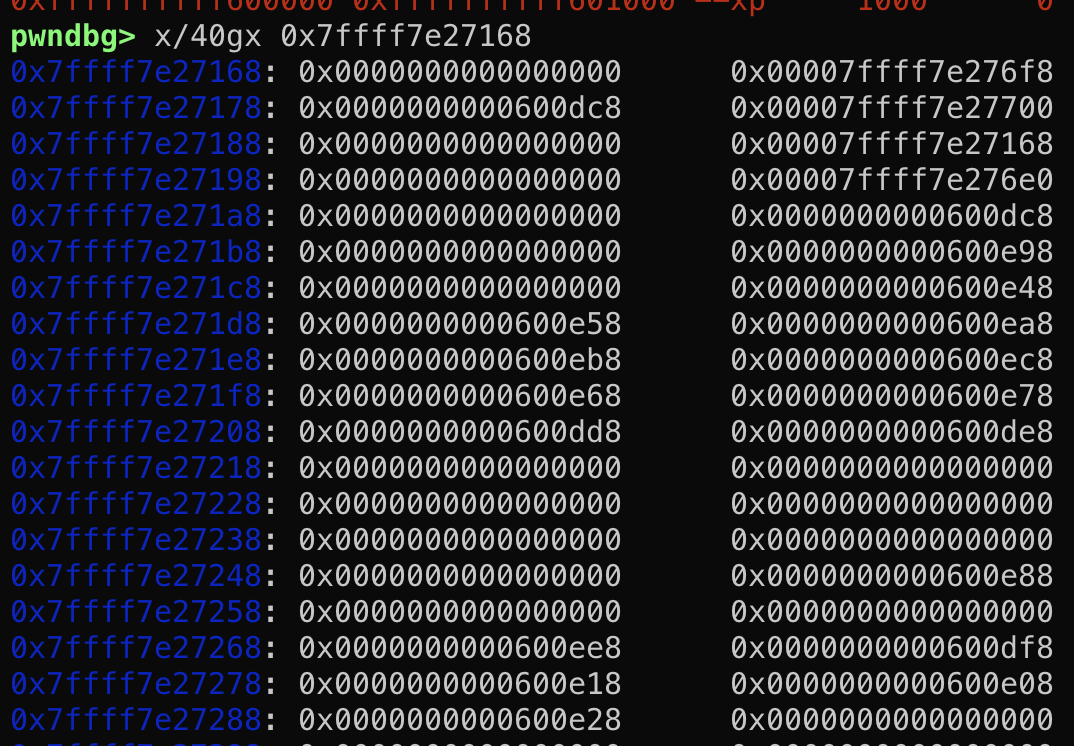 然而这个结构体在main函数的时候其实是保存在栈上的!
然而这个结构体在main函数的时候其实是保存在栈上的!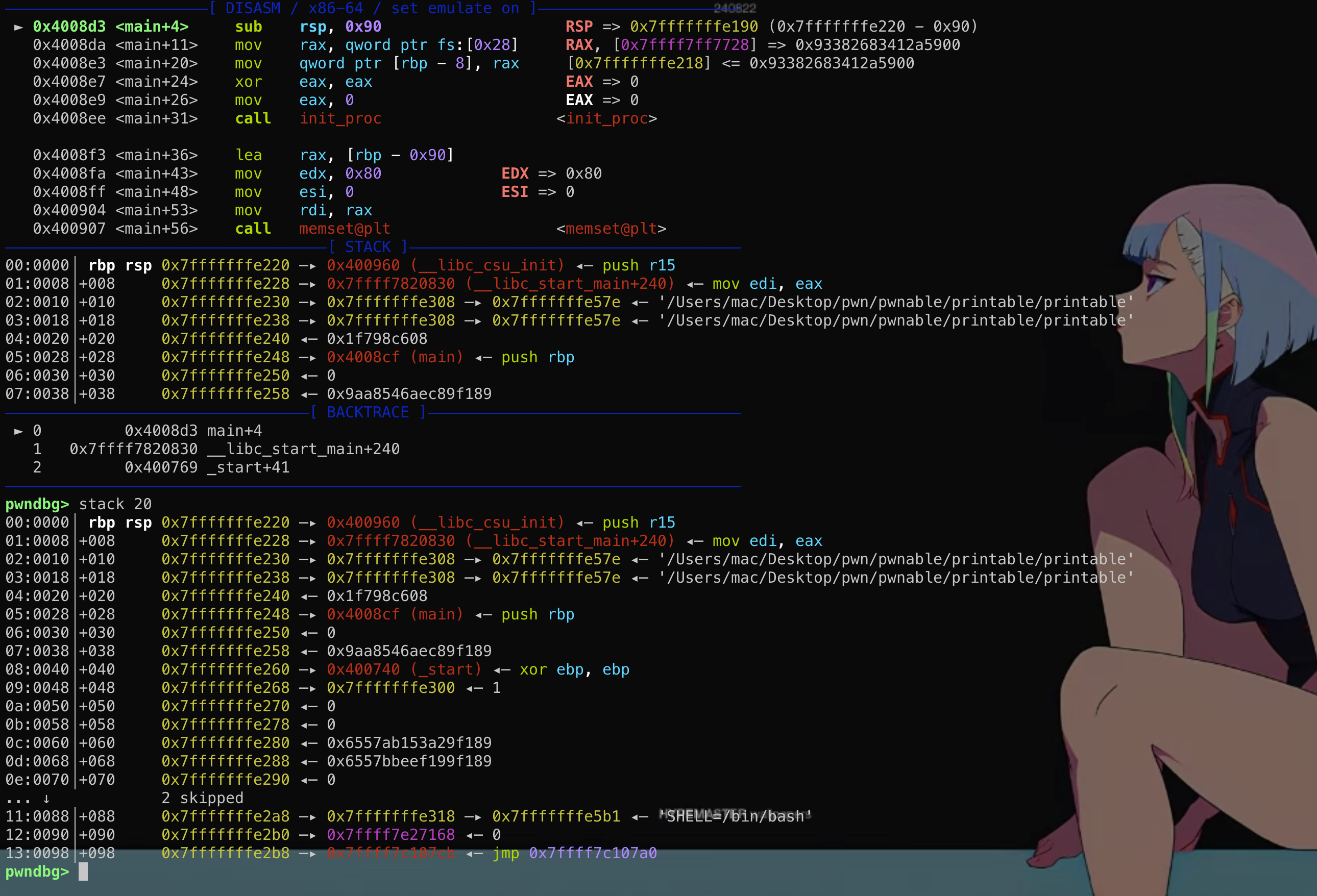 这段结构体是可写的,那么如果能够通过格式化字符串等漏洞往栈上这个结构体内固定偏移写入数据,就能控制fini_array到可控地址从而使劫持exit后到程序流!
这段结构体是可写的,那么如果能够通过格式化字符串等漏洞往栈上这个结构体内固定偏移写入数据,就能控制fini_array到可控地址从而使劫持exit后到程序流!{kind=link}
{kind=link}
{kind=link}